文献阅读: To FUSE or Not to FUSE: Performance of User-Space File Systems
To FUSE or Not to FUSE: Performance of User-Space File Systems
论文作者:Bharath Kumar Reddy Vangoor, Stony Brook University; Vasily Tarasov, IBM Research-Almaden; Erez Zadok, Stony Brook University
发表会议:FAST'17: Proceedings of the 15th Usenix Conference on File and Storage Technologies
发表时间:February 2017
FUSE,即 Filesystem in USErspace,用户空间的文件系统。对于传统的宏内核而言,文件系统都实现在内核态,而 FUSE 这项技术使得可以在用户空间实现文件系统。用户空间文件系统通常用于进行原型验证,这是因为它具有开发便捷的特点。然而,在用户空间实现文件系统却带来了巨大的性能开销,因此 FUSE 颇具争议:FUSE 能否用于开发生产环境下的文件系统。本文对 FUSE 进行了性能追踪和统计,并在真实负载下分析了 FUSE 的性能瓶颈。
FUSE design
High-Level Architecture
从高层视角来看 FUSE,一个 FUSE 文件系统包含两个部分:
- 内核态 FUSE driver,它对用户态暴露
/dev/fuse,用于用户态 FUSE deamon 和 内核通信,并负责管理和分发来自应用程序的 request - 用户态 FUSE library,用户态的 FUSE deamon 基于 FUSE library 编写,实际上,这个库对 FUSE 操作进行了更高层的封装,使得基于 FUSE 构建文件系统更加容易
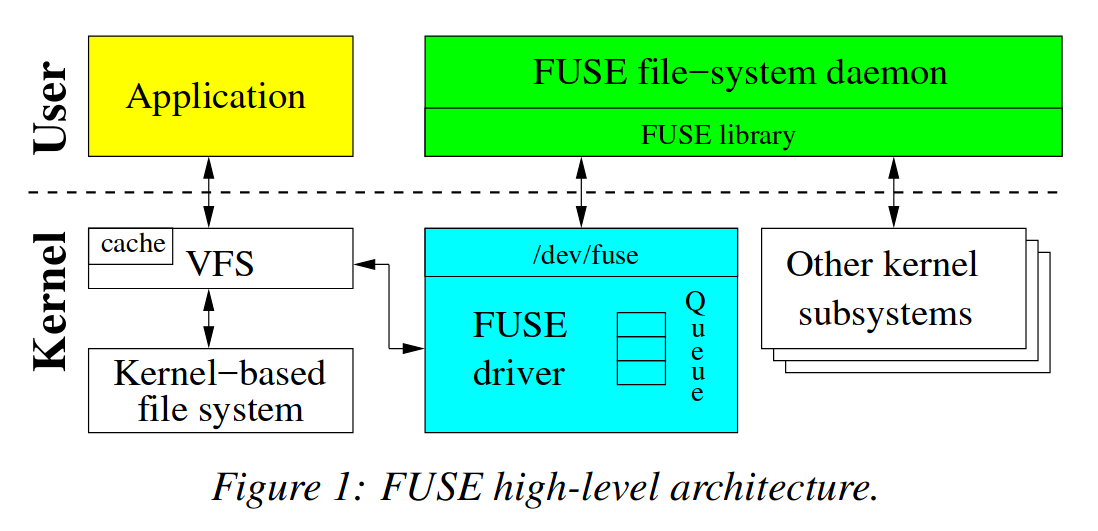
FUSE 的简化工作流程如下:
- 用户空间 Application 发起对 FUSE 文件系统的文件操作
- 内核态 VFS 将操作请求路由到 FUSE 驱动程序
- 根据请求类型,创建 FUSE request,并挂载到队列中
/dev/fuse分发 request 给用户态的 FUSE deamon- FUSE deamon 根据收到的 request 执行对应的处理
- 处理结束后,FUSE deamon 通过
/dev/fuse发送 reply 告知内核 - FUSE driver 将请求项从队列删除,将操作结果返回给用户程序
Implementation Details
User-Kernel Protocol
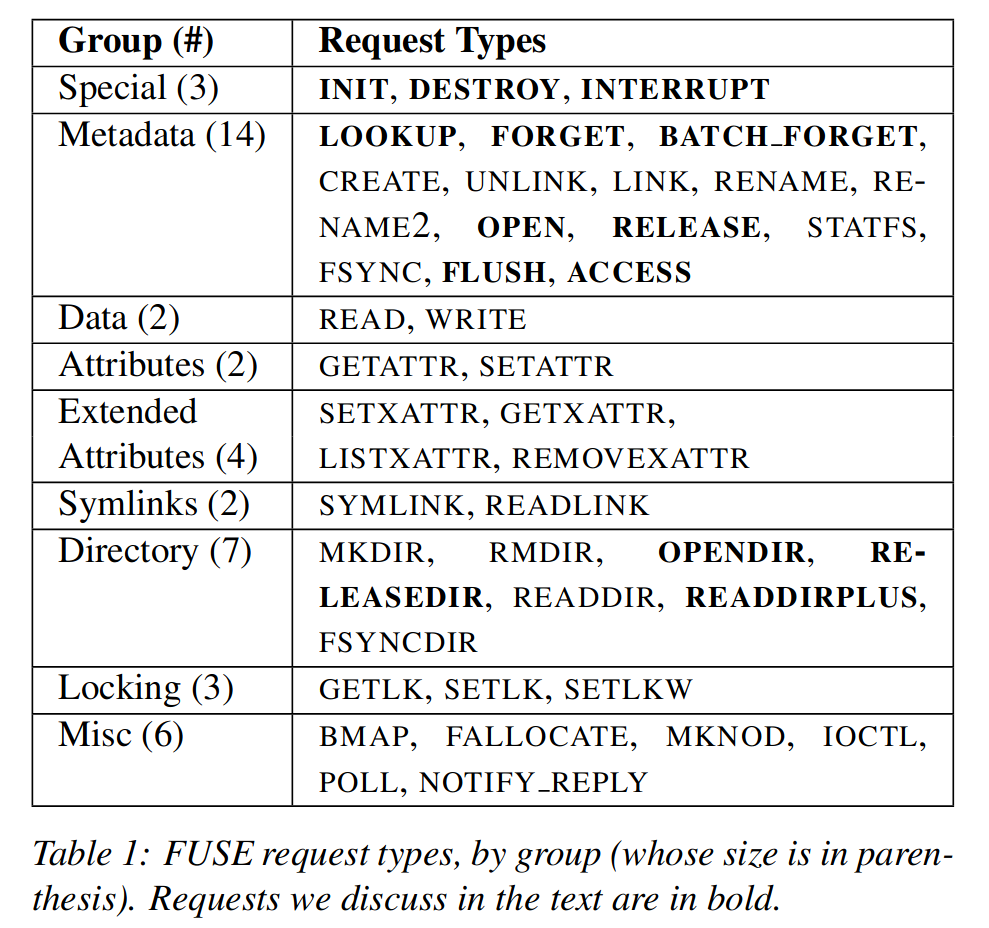
上表总结了 FUSE 的 43 种 request,其中加黑的与 VFS 操作语意有些出入。
- INIT:当文件系统被挂载时由内核产生。用户和内核确认
- 协议版本
- 相互支持的能力集合(如 READDIRPLUS 的支持)
- 各种参数的设置(如 FUSE 预读大小、时间粒度)
- DESTROY:当文件系统被卸载时由内核产生。FUSE deamon 执行清理工作,任何与该文件系统 request 都无法被送往用户空间处理,而后,FUSE deamon 将退出
- INTERRUPT:由内核发出,用于停止某个 request(如一个等待 READ 的进程终止了)。
sequence#:每一个 request 都有一个唯一的 sequence# 用于识别,该序列号由内核分配
node ID:一个 64 位的无符号整数,用于在内核和用户空间识别 inode
- LOOKUP:进行 path-to-inode 转换,每次 lookup 一个 inode 时,内核就将其放入 inode 缓存
- FORGET & BATCH_FORGET:将 inode 从缓存中删除,并通知 FUSE deamon 释放相关数据结构
- OPEN:打开文件,FUSE deamon 可以选择性地返回一个 64 位的文件句柄,而后每一个与该文件有关的 request 都将带有这个句柄
file handle:FUSE deamon 可以利用该句柄存储打开文件的信息,例如在栈文件系统中,FUSE 文件系统可以将底层文件系统的描述符存储为 FUSE 文件句柄的一部分
- FLUSH:关闭文件
- RELEASE:之前打开的文件没有任何引用时发出
- OPENDIR & RELEASEDIR:与 OPEN 和 RELEASE 语义相同,但操作对象是目录文件
- READDIR & READDIRPLUS:返回目录项,READDIRPLUS 还会返回每个项的元数据信息
- ACCESS:内核用于确认用户进程对于某个文件是否具有访问权限
Library and API Levels
在用户空间 FUSE 的 API 严格来说有两层,底层 API 负责实现与内核 FUSE driver 的基本通信,基于底层 API 所构建的高层 API 用于方便用户态文件系统的编写。
底层 API vs. 高层 API \(\approx\) flexibility vs. development ease
底层 API:
- 接收并翻译来自内核的 request
- 发送格式化的 reply
- 为文件系统的配置和挂载提供便利
- 为内核和用户空间隐藏可能的版本差异
高层 API 包含更多语义,尤其是隐藏了 path-to-inode map 的细节,从而高层 API 中都是直接操作文件路径的方法。
Queues
FUSE 的队列存在于内核态,由 request 构成。FUSE driver 通过管理 request 队列进行 request 调度。FUSE 中包含 5 个不同的队列,分别用于管理不同种类的 request,同时,不同队列中的 request 具有不同的优先级,当 FUSE driver 决定发送哪个 request 给 FUSE deamon 时,优先级就会起到作用。
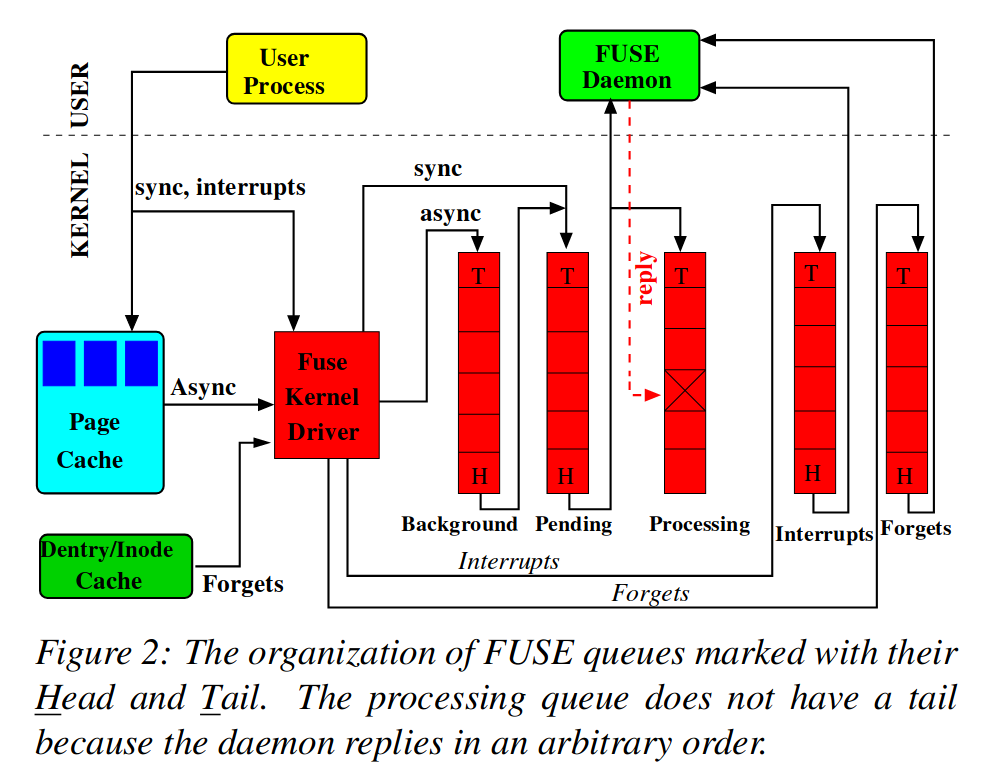
FUSE 中的 5 个队列名称及其对应功能:
| 名称 | 功能 |
|---|---|
| interrupts | INTERRUPT request |
| forgets | FORGET request |
| pending | 同步 request |
| processing | 正在处理的 request |
| background | 异步 request |
FUSE Workflow
Linux FUSE 文档1中给出了一个 FUSE 的工作流程:
1 | |
- 用户程序发起文件系统操作
rm /mnt/fuse/file - FUSE deamon 读
/dev/fuse,但此时 request 队列为空,因此触发request_wait(),进入睡眠 - 用户程序触发系统调用
sys_unlink(),内核路由到 FUSE 操作函数,由将操作对应 request 加入 pending 队列,并唤醒 FUSE deamon - FUSE deamon 被唤醒后,将 requset 从 pending 队列移除,并将其加入 processing 队列
- FUSE deamon 返回用户空间后,根据读到的 request 进行相应自定义操作
- FUSE deamon 执行完操作后,向
/dev/fuse写 reply,将对应 request 从 processing 队列移除,并唤醒等待的用户程序 - 用户程序从内核系统调用返回,完成操作
Instrumentation
为了研究 FUSE 的性能表现,研究人员利用底层 API 实现了一个栈(堆叠式)文件系统 Stackfs,直接建立在 ext4 文件系统之上,这样做的原因:
- 大部分基于 FUSE 的文件系统都是堆叠式的
- 减少 FUSE deamon 的复杂度,这样能够尽可能还原 FUSE driver 和 FUSE library 性能表现
测试记录了在请求处理各个阶段(包括内核和用户态)花费的时间,为此,引入一个 43x32 的二维数组,行表示 43 种不同的 request,列表示以 2 为底的对数坐标时间。
策略:在内核空间实现 3 个数组,分别用于监视
background、pending 和 processing 队列;在用户空间实现 1
个数组,用于监视 FUSE deamon 处理一个 requset 的时间
机制:内核空间利用了
fusectl,用户空间利用了 SIGUSR1
Methodology
FUSE 配置、负载信息和实验平台,在此不一一列举。
实验中 FUSE 氛围两种配置:基本配置 StackfsBase 和 优化配置 StackfsOpt,优化配置开启了 FUSE 的所有增强功能:(1)写回缓冲;(2)
max_write设置为 128KiB;(3)FUSE deamon 多线程;(4)splicing(零拷贝)对所有操作开启
Evaluation
测试结果汇总在表格中,其中的百分比表示相对于 ext4 性能变化,得到总体性的结果如下(原文翻译):
绿色区域:性能下降在 5% 以下 黄色区域:性能下降在 5-25% 之间 橙色区域:性能下降在 25-50% 之间 红色区域:性能下降在 50% 以上
Observation 1. 测试结果由于负载、外设和 FUSE 配置而导致的差异范围为 -83.1%(files-cr-1th [row #37])到 +6.2%(web-server [row #45])
Observation 2. 对于大多数负载,FUSE 的优化配置能显著提升性能,如 web-server [row #45],StackfsOpt 将性能提升 6.2%,而 StackfsBase 导致性能下降 50%。
Observation 3. 尽管对于一些负载优化配置能提升性能,对于另一部分,优化配置反而导致性能下降。如 files-rd-1th [row #39],StackfsOpt 导致性能下降 35%,下降幅度大于 StackfsBase 配置。
Observation 4. 在 Stackfs 性能最佳的配置中(包括 StackfsOpt 和 StackfsBase),只有 2 个创建文件的负载(共 45 个工作负载)在红色区域:files-cr-1th [row #37] 和 files-cr-32th [row #38]。
Observation 5. Stackfs 的性能与底层设备有很大关系。如对于顺序读 [row #1-12],Stackfs 在 SSD 上没有性能下降,而在 HDD 上有 26% 到 42% 的性能下降。而对于 mail-server [row #44] 这个负载,情况恰恰相反。
Observation 6. 对于所有的写负载(顺序的和随机的),至少有一个 Stackfs 配置能够在使用 HDD 和 SSD 的情况下都在绿色区域。
Observation 7. 对于 HDD 和 SSD,顺序读 [rows #1-12] 的性能都在绿色区域;然而对于运行在 HDD 上的 seq-rd-32th-32f [rows #5-8],性能位于橙色区域。随机读的结果 [rows #13-20] 在所有 4 个区域均有分布。另外,对于 HDD 和 SSD,性能随着 I/O 规模的增加而上升。
Observation 8. 总体上来说,相比于数据密集型负载 [rows #1-36],Stackfs 在元数据密集型和宏工作负载 [rows #37-45] 下明显性能更差,尤其是对 SSD 而言。
Observation 9. 相较于 Ext4,Stackfs CPU 利用率更高,在 +0.13% 到 +31.2% 之间;同样的,每操作的 CPU 周期数也提升了 1.2\(\times\) 到 10 \(\times\) 不等。这一行为在 HDD 和 SSD 上表现一致。
Observation 10. 对于大多数负载,StackfsOpt 的每操作的 CPU 周期数高于 StackfsBase。但对于负载 seq-wr-32th-32f [rows #25–28] 和 rnd-wr-1th-1f [rows #30–32],StackfsOpt 的每操作的 CPU 周期数更低。
- 1.https://www.kernel.org/doc/html/next/filesystems/fuse.html#kernel-userspace-interface ↩︎
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!