文献阅读: The BSD Packet Filter: A New Architecture for User-level Packet Capture
The BSD Packet Filter: A New Architecture for User-level Packet Capture
论文作者:Steven Ray McCanne, Van L Jacobson
发表会议:USENIX'93
发表时间:January 1993
0 导览
1992 年的这篇文章首次提出了 BPF,即 “BSD Packet Filter”。最初 Unix 中的数据包过滤器是基于 stack 设计的,在 RISC CPU 中运行效率不高。BPF 基于 register 设计,比原来的设计快了 10 倍,整体性能比相同环境下的 NIT 快 100 倍。
本文主要介绍了 BPF 的设计思路,包括 BPF 的整体架构、理论模型(CFG)、伪语言翻译器、BPF 指令集,并给出了一些 BPF 过滤器的例子,最终通过测试验证了 BPF 的高效性。在文章主要内容的最后,给出了一些 BPF 已有的应用,从侧面说明了 BPF 设计的合理性,是真正能够运用到生产环境中的工具。
1 Introduction
BPF 的架构设计特点:
- register-based:在 RISC CPU 中能够得到更有效的实现,stack-based 面临存储墙问题
- non-shared buffer model:得益于更大的地址空间
2 The Network Tap
BPF 的 2 个主要部件:
- the network tap:从网络驱动收集包并复制给侦听程序
- the packet filter:决定是否接受包,以及复制多少
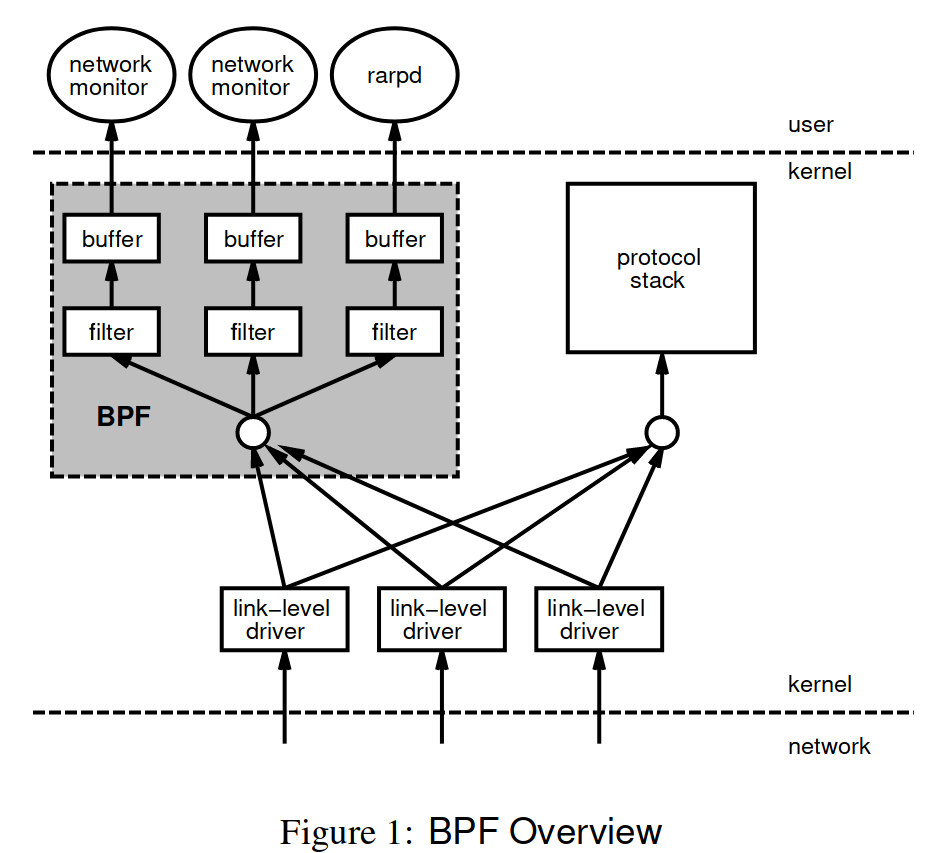
当网络数据包到达时:
- link-level driver 调用 BPF
- 数据包经过 user-defined filter
- filter 决定哪些包可以被复制到 buffer
2.1 Packet Filtering
BPF 相比于 NIT 性能提升的区别是 BPF 在 filter 之后才进行数据包的拷贝,而 NIT 是先进行拷贝再进行过滤,因此 NIT 浪费了许多 CPU 周期。
2.2 Tap Performance Measurements
针对 BPF 和 NIT 的 packet-to-buffer 时间进行两组测试:
- accept all
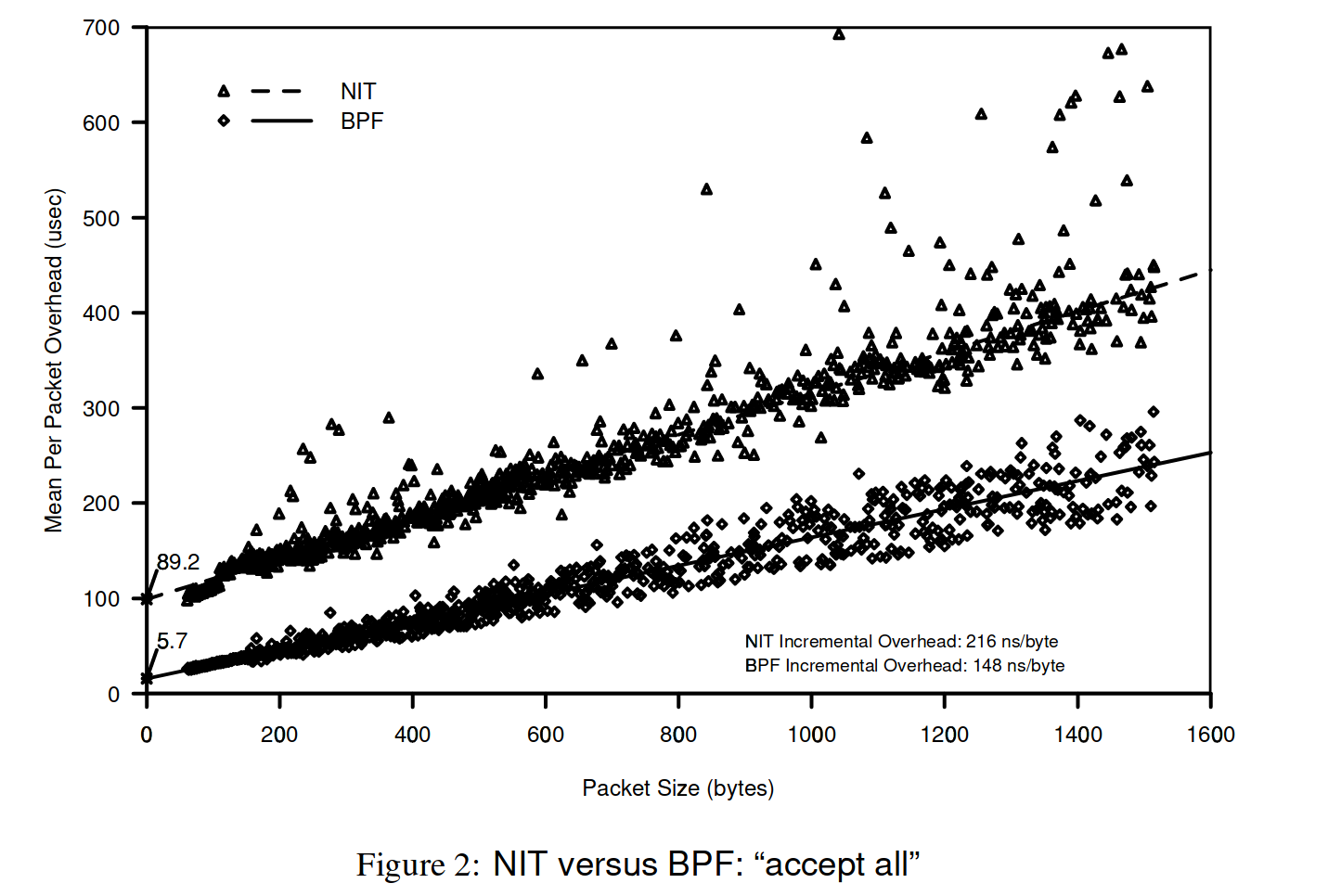 BPF 相比 NIT
有更缓慢的增长,y-截距是每个数据包处理的固定开销,BPF:6us,NIT:89us
BPF 相比 NIT
有更缓慢的增长,y-截距是每个数据包处理的固定开销,BPF:6us,NIT:89us - reject all
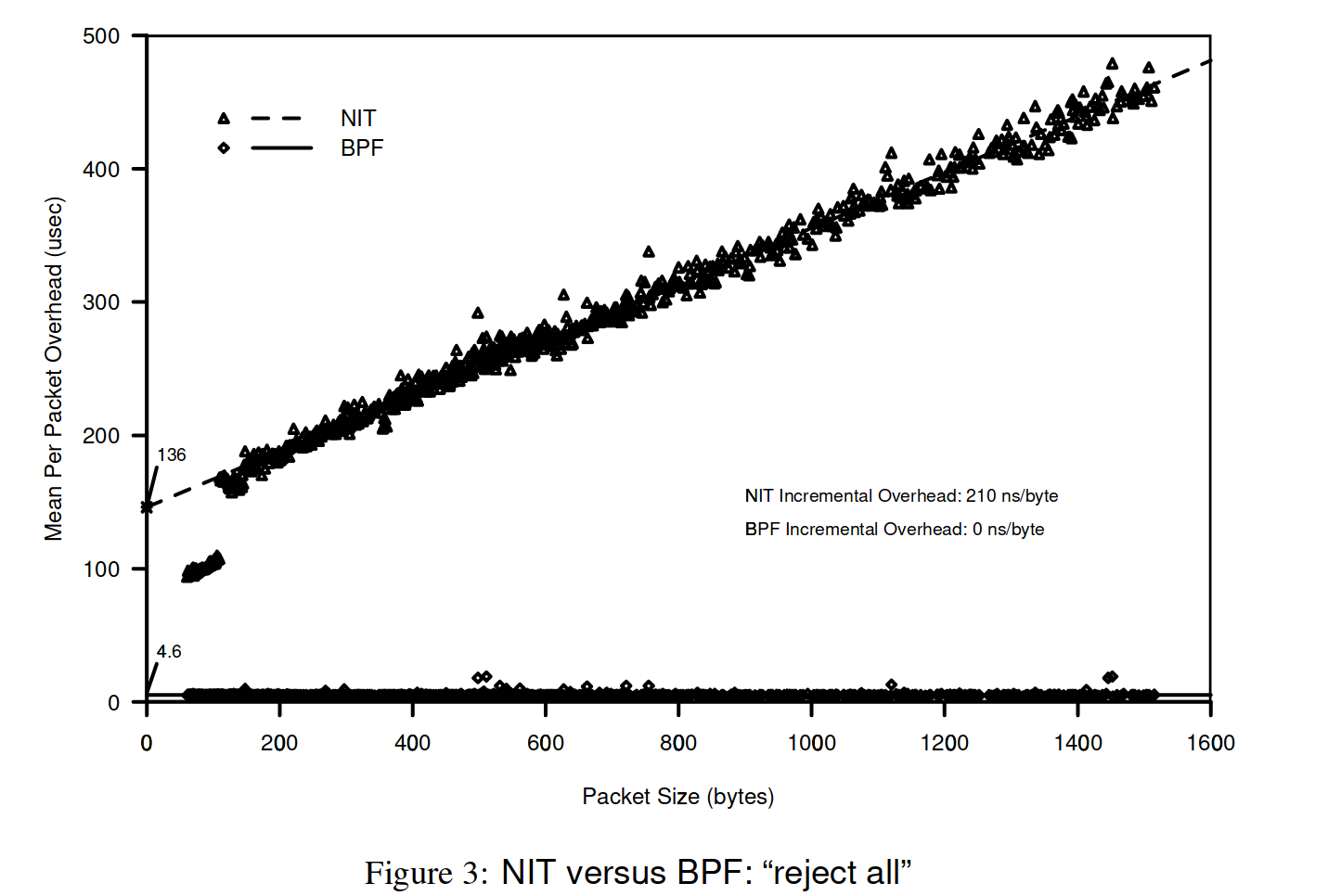 BPF 无增长,NIT
持续增长,最终甚至差了 2 个数量级。
BPF 无增长,NIT
持续增长,最终甚至差了 2 个数量级。
上面的测试结果体现了将 filter 和 tap 2 个单独的模块集成到一个单元中带来的巨大性能优势。
3 The Filter Model
Assuming one uses reasonable care inthe design ofthe buffering model, it will be the dominant cost of packets you accept while the packet filter computation will be the dominant cost of packets you reject.
大部分应用拒绝的包数远远大于接受的包数,因此 filter 的性能至关重要。filter 本质上是一个布尔函数,因此有 2 种表示方法:
- boolean expression tree/CSPF 描述表达式本身,契合于 stack-based machine(对于一个表达式,我们可以利用栈来递归地进行求值)
- CFG(控制流图) 描述表达式的执行流,更契合于 register-based machine
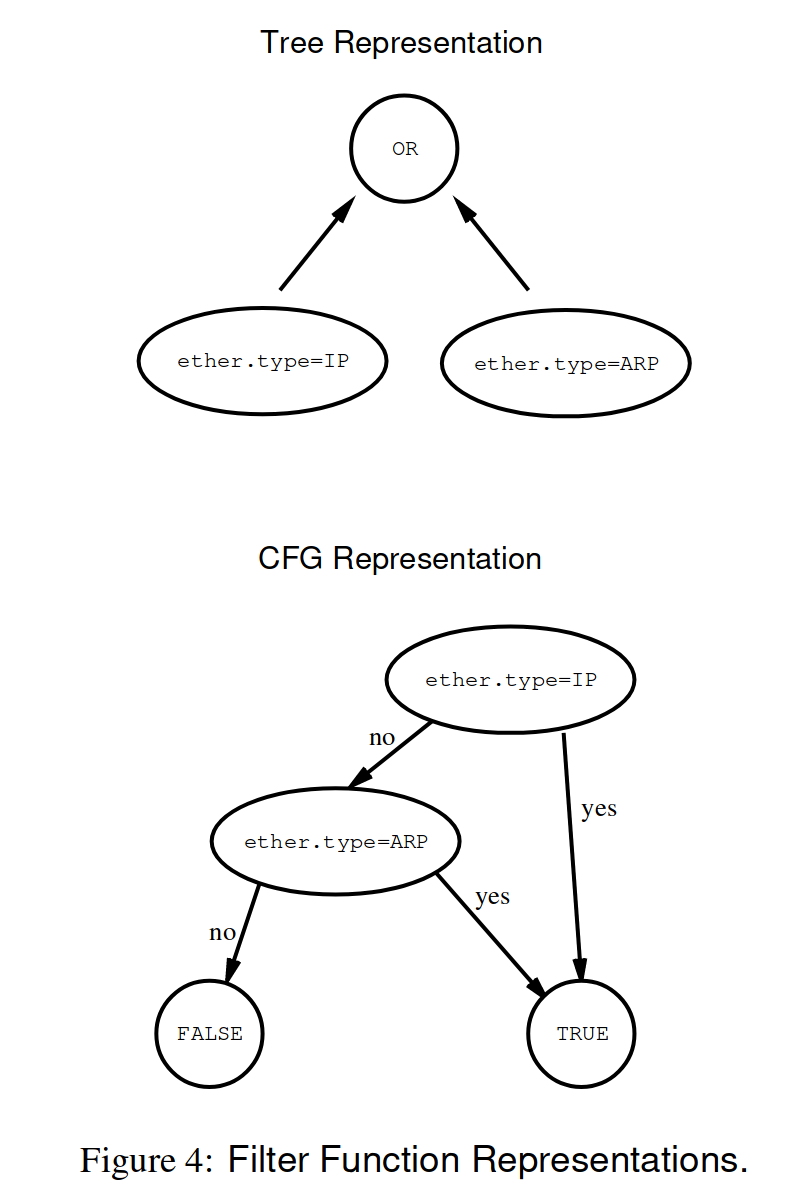
3.1 The CSPF(Tree) Model
表达式求值实现上的弊端:
- 需要模拟栈:额外的 add/sub 指令来控制栈指针寄存器,以维护一个栈,且频繁的栈访问成为性能瓶颈
- 通常包含冗余计算:如
a | b,我们无需将a和b的值都计算出来。这对于网络包过滤是很关键的,因为某些子表达式需要经过多层网络栈才能求值
另一方面,CSPF 处理的数据有长度限制。
尽管 CSPF 有诸多限制,但是它提出了很新颖的思路:
- 在内核中加入一个伪语言翻译器,以实现过滤器
- 将过滤的包视为字节数组,从而独立于网络协议
3.2 The BPF Model
基于 CFG 的 BPF 的伪机器(也就是虚拟机/翻译器)设计基于以下设计约束:
- 协议无关:将包视为字节数组
- 通用(指令)
- 包数据引用最小
- 通过 C 语言的
switch语句译码:为了保证译码效率,采用单地址格式编码 - 抽象机器的寄存器需要在物理寄存器中驻留
这些约束导致采用累加器型机器是最为合适的。
3.3 The BPF Pseudo-Machine
3.4 Examples
3.5 Parsing Packet Headers
这三节介绍了 BPF 的指令集设计,给出了一些例子,并解释了
4 * ([k] & 0xf) 这一寻址方式的设计意图。
BPF 虚拟机的操作对象包括:一个累加器、一个寄存器、一个存储器、数据包和一个隐式的 PC。
BPF 的指令类型:
- 访存指令在累加器/寄存器和存储器/数据包间移动数据
- 运算指令将累加器中的值和立即数进行运算
- 分支指令根据寄存器中的值是否满足条件改变 PC
- 返回指令返回过滤器的最终判断结果,为 TRUE 则接受数据包
- 若干杂项指令
3.6 Filter Performance Measurements
通过比较 BPF 和 CSPF 过滤器模型的执行指令数,可以发现 BPF 存在显著的性能优势。
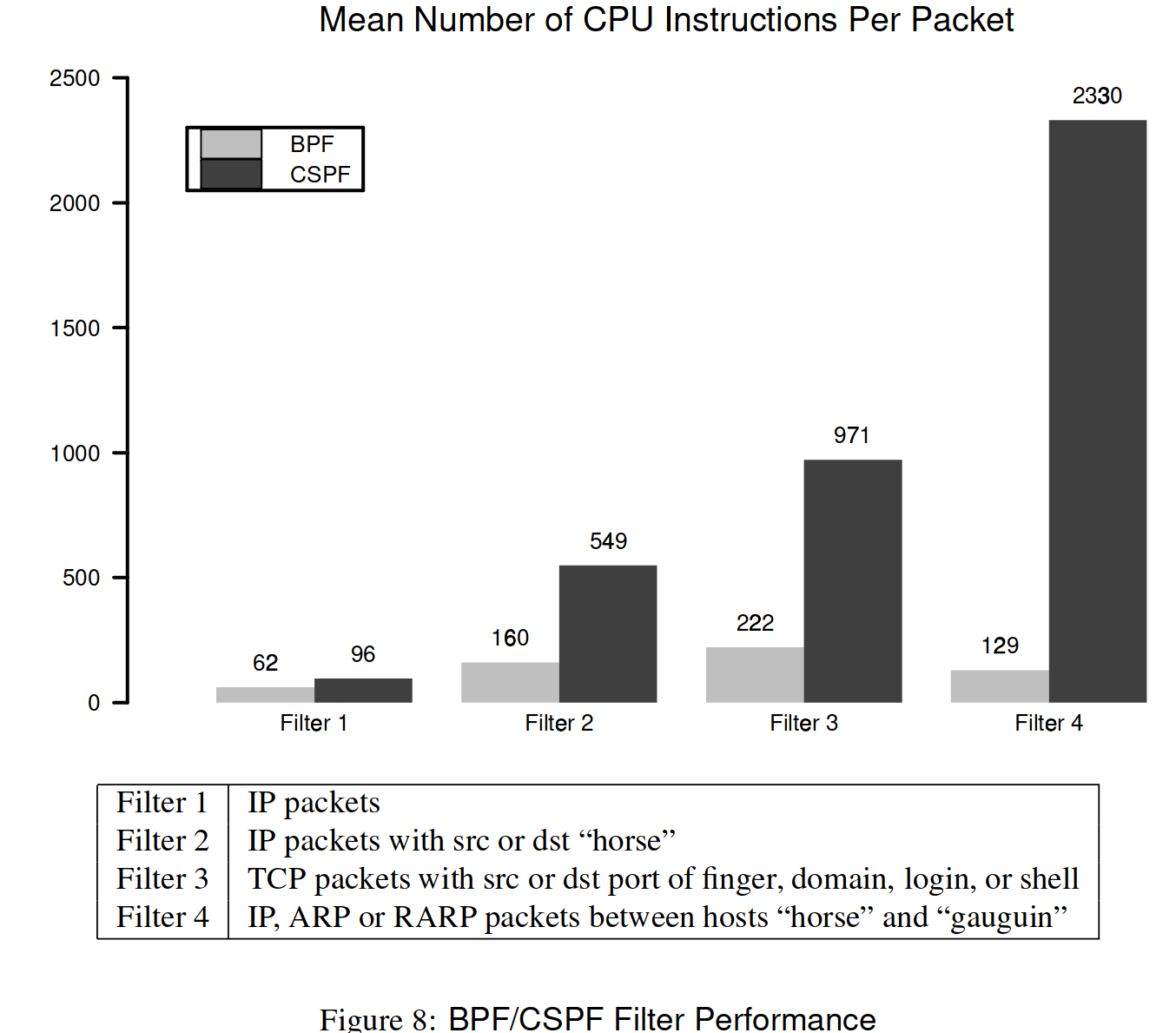
- Filter 1:BPF 快了 50%
- Filter 2:BPF 快了 240%,这主要是由于 CSPF 一次只能处理 16 位的数据,处理一个 32 位数据需要两次运算
- Filter 3:更大的性能差距,这是因为 CSPF 中有许多重复运算
4 Applications
BPF 的主要应用:tcpdump、arpwatch 等。
5 Conclusion
BPF 是一个高效的、可伸缩的、可移植的网络监控模型,已经可以运行在大部分的 BSD 发行版上。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!